






Industry starved for data?
May 14th, 2008
PubMatic just released a new AdPrice Index which was immediately picked up by a rather frightening number of news sources: Business Week, ClickZ, The Washington Post to name just a few.
First off, serious kudos to the PubMatic team for releasing these numbers. This post is in no way meant to be negative to them, they’ve got a great service and by releasing this index they are upping the bar for everybody else — I wish everybody released a monthly report indicating their view of the market. Note that Rubicon had previously released a less statistical and more narrative Q1 Ad Network Market Report.
What I find somewhat surprising is the level of buzz the PubMatic release generated. Although I’m certain that the statistical quality of their numbers is good I want to point out that there is an inherent sample bias for the Index not only on the publishers selected but also the ad-inventory being analyzed. The publishers are ones that chose to signup for the PubMatic service to help them optimize revenue from Ad Networks. Next, PubMatic’s numbers reflect only the subset of inventory that was sent to PubMatic and the media dollars that inventory made based on the networks that work with PubMatic’s platform.
So even taking these numbers with a grain of salt there are probably enough pubs & networks that something happened in April… so surely it must be time to PANIC because we’re in this massive recession and online advertising is going to dry up and die … right?
Well, I’ll let you in on a little secret. Agencies have quarterly budgets. Each ad-campaign has a certain target revenue that needs to be spent by the end of the quarter, and since most publisher forecasting systems are prone to error there are a large # of campaigns that find that their guaranteed buys have under-delivered and are now nearing the end of the quarter with significant money left to spend. Where do they go? Ad-Networks. Through years at RM we saw the same thing year after year, quarter after quarter. March, June, September and December were always high in revenue, with December being particularly great with some nice “end of year” budgets moving to remnant display. So my guess — what we’re seeing is a normal cyclical trend, where Q1 budgets moved to Ad-Networks in March, disappeared in April and hence PubMatic saw a significant drop in revenue. Of course I could be wrong, but either way the media should certainly stop predicting the impending doom of the online-ad market.
More important than the actual numbers, I think that the reaction to this event shows how desperate we are for insight and visibility into what’s going on. How much money is flowing, and to which parties? What I’d like to see is the Quantcast 100 Advertising Index. Impressions, CPMs & revenue for the aggregate top-100 sites on the Net — now those would be numbers to analyze and report on!
Networks: Friend or Foe?
May 2nd, 2008
There’s a great post from Christian Kreibich dissecting Adsense’s JavaScript. Near the very bottom there’s a little hidden nugget that I’m not sure Christian quite got the consequence of that I’d like to elaborate on (don’t worry if you don’t understand JS, I’ll explain!):
if (specialSites[doc.domain] && doc.domain == "ad.yieldmanager.com") {
var d = doc.URL.substring(doc.URL.lastIndexOf("http"));
win.google_page_url = d;
win.google_page_location = doc.location;
win.google_referrer_url = d;
} else {
win.google_page_url = doc.referrer;
if (! isTooSmall(win, doc)) {
win.google_page_url = doc.location;
win.google_last_modified_time = Date.parse(doc.lastModified) / 1000;
win.google_referrer_url = doc.referrer;
}
}
Now you don’t need to be technical to get this. That first line basically says this — “If this is coming through ad.yieldmanager.com do something special.” As most of you probably know, ad.yieldmanager.com is the serving domain used by the Right Media Exchange, which of course encompasses a significant chunk of remnant inventory being sold online today. So what Google is doing with this code is something “special” in case the publisher’s referring domain contains the url ‘ad.yieldmanager.com’ — when the publisher is some party on the Right Media Exchange.
The next couple lines do some special manipulation on the referring URL. Now, it’s most likely that Google is simply pulling out the “&u=http://site.com” parameter (the “URL.lastIndexOf()” ) commonly seen in yieldmanager.com tags, which would be the URL of the actual website hosting the ad. Google could then be using this to drive contextual results in case it is wrapped in one too many IFRAMEs and can’t pull out the “document.url” parameter it normally uses. But it bring to light another possibility.
Rather than accuse Google of doing something bad (which they probably aren’t), let’s move this to a hypothetical situation — a network (Network Evil) is buying from a publisher (Pub Good) and wants to extract additional information to build a more detailed behavioral profile of the end user. “Good Pub” knows the age and gender of his users and passes that to his adserver for premium advertisers. This particular publisher doesn’t share this information with ad-networks for privacy reasons and only uses it for direct brand advertisers where he hosts the actual creative.
One of the easiest ways for the publisher to pass information to his adserver is to insert a query string parameter at the end of an ad-call. For example, I could append “&gender=male&age=21″ at the end of my IFRAME ad-call. My adserver could then interpret these values and my media-sales team can then target specific advertisements to men or women of certain ages on my site. The problem with this method is that ‘Network Evil’ could easily sniff this information
All ‘Network Evil’ has to do is log and then harvest data from referring URLs. With a little bit of clever javascript (or server side code) ‘Network Evil’ can dig through the publisher’s referring URL and use the age and gender passed in the querystring to better target his ads and even store this information in his own cookie.
Of course with this simple example there are a number of easy workarounds. First off, any smart publisher won’t pass “&gender=male&age=22″ into the querystring and instead use obfuscated or encrypted parameters. This makes extracting the information much more difficult. But, as I’ve shown before in this post, there are some clever tricks you can do with Javascript already to increase how much data you can retrieve from a partner. Rather than post a list of nasty ideas and get them in peoples heads I’ll leave things to your own imagination.
This brings me to the whole point of this post. It seems these days that everybody is an ad-network. We have vertical networks, publisher networks, behavioral networks, data networks, optimization networks, cpa networks…. each of which when it comes down to is buying and selling online media in some shape or form — often from each other! This is the problem — our partners are our competitors and our competitors are our partners.
The question becomes — how do you monitor and control what your partners/competitors do with the inventory or creatives you give them? How do you stop someone form stealing behavioral data? How do you audit the creative an ad-network shows? Of course you can put contractual obligations in place, but how do you audit those policies? How do you audit your partner’s partners? If one network buys male users from you and then resells them to the another network, how do you control and audit that neither network is storing that data for future use?
To date the answer has generally been two things: rudimentary technology solutions and trust. When it comes down to it, most companies simply trust that their buyers and sellers are going to adhere to the negotiated contract terms. Some may go an additional step and place some rudimentary technology solutions in place to help audit, but honestly true auditing is incredibly difficult and challenging (look at Errorsafe which is still happening!). This is why slip ups continue to happen. Data leaks, adult creatives end up on premium sites and brand ads are shown on spyware apps.
Is this really the way ads are still being traded in 2008?
Redirects and Integration, Part II: Hacking Around the Browser
April 17th, 2008
In my last post I talked about redirects and the limitations they posed for online advertising. In this post I’m going to discuss the various workarounds that people have put in place to address the problem. I’m primarily going to focus on serving speed & the “one-way” challenges of redirects as there isn’t much that can be done to address the fact that redirects are inherently insecure.
Fundamentally when you are talking about “integrating” two different serving systems there are two key driving factors: tracking information and influencing the decision. In most cases tracking information is for either transparency or behavioral information. Influencing the decision is also often related to behavior as it’s close to impossible to transplant data from one cookie domain to another. So let’s look at three little ‘hacks’ that people do to make systems play nice.
Replacing a redirect with a tracking pixels
One of the primary reasons why agencies operate their own adservers is to be able to track the # of impressions that their publishing partners are serving. Yet a much simpler method of counting ads that doesn’t involve an entire redirect is to place an “impression tracking pixel” that the publisher (or network) shows on every ad call.
Let’s compare how an impression-tracking pixel impacts the serving speed compared to a more traditional redirect If both a publisher and an advertiser are using a serving system and are using standard redirects (or ad tags) to integrate, each ad call will result in three consecutive requests:
Call 1, Publisher’s Adserver. The first call obviously goes over to the publisher’s serving system. When the publisher’s adserver chooses an adserver he returns to the page either a 302 redirect or some javascript from the advertiser’s serving system. Effectively redirecting the user.
Call 2, Advertiser’s Adserver. In this call the advertiser receives the request, logs an impression and then spits back some HTML (or javascript) that tells the browser to download the ad, generally from a content delivery network (CDN).
Call 3, Creative Content. In the third call the browser requests the actual GIF/JPG/SWF file from a content delivery network and displays the ad.
If each call takes 250ms the total time to serve this ad will be 750ms as no call can occur until the prior one has fully completed. The browser doesn’t know where which advertiser adserver to request content from until he has fully received the publisher’s redirect and then the actual SWF file can’t be downloaded until the advertiser’s adserver has responded with the appropriate HTML.
When an advertiser passes the actual creative over to the publisher and includes an impression tracking pixel the ad-call sequence changes a bit.
Call 1, Publisher’s Adserver. The first call is still to the publisher’s serving system, except rather than returning the actual ad-tag (or redirect) to the advertiser the publisher’s system returns two things. One a call to the actual creative (SWF/GIF/JPG) hosted on his CDN and then a second pixel call to the advertiser’s impression tracking pixel.
Calls 2&3, Creative & Tracking Pixel. Because the user’s browser received both instructions it can now proceed to download both the creative and the tracking pixel in parallel.
If each call takes 250ms then the total time to serve this ad will be 500ms, 250 for the first publisher call and then another 250 for the creative & tracking pixel in parallel.
Benefits: The biggest benefit of the impression tracking pixel approach is that it decreases the time to serve an individual ad — something that will reduce discrepancies and increase the quality of the end user’s experience.
Drawbacks: Of course there are drawbacks with this approach. Trafficking both a creative and it’s associated impression tracking pixel is more work than a simple ad-tag. It also requires more coordination between the advertiser and the publisher
“Forking” an ad-call with an impression pixel
Impression pixels do not have to solely exist instead of a redirect. In fact, they can also be used to supplement existing ad-calls and let third parties “listen in” on an impression stream without giving them the power to manipulate an ad. For example, let’s say that a network uses the Right Media ‘NMX’ platform for their network adserving but is unhappy with the amount of information that he receives from the reporting systems. Said network’s advertisers demand more information from their media-buys — what can he do?
Obviously one answer is to add a redirect to every ad call — this quickly becomes complicated though as the network will have to host the actual gif & flash files, somewhat defeating the purpose of using a 3rd party network adserver. Also, many publishers won’t accept third party served ads from unknown adservers, posing an additional challenge when trying to buy tier-1 inventory.
Another way to address the issue is to insert a tracking pixel into every creative. On every ad-call the network fires off a pixel to his own tracking server which contains the key information that he is interested in — say — creative ID, publisher ID and referring URL. He can then log this information and provide the advertiser with the detailed reports showing exactly where his ads appeared without having to reinvent an adserver!
Using AJAX to load 3rd party content
AJAX has gained a lot of popularity recently. One way that people can integrate two serving systems is by inserting a small bit of javascript that loads the 3rd party content required to either track information or make a decision directly into the browser. For example, let’s say a network wants to know whether a behavioral data provider has valuable data on a user. If the behavioral partner he receives the impression and if not the publisher sends the impression over to one of his regular networks. He could insert a small bit of javascript that sends a request browser-side and loads the behavioral advertiser’s cookie data from the third party domain.
There are some benefits to this approach — timeouts could be set on the actual request limiting the potential slow-down. Also, since the third party isn’t in the redirect stream he doesn’t get full control over the entire impression. The downside is that the decision is made on the client side. This introduces a whole new set of challenges around tracking & writing cross-browser compatible JS.
All these methods are hacks
You’ve probably realized by now that most of the workarounds involve tricking the browser to load some content from different serving systems. Some schemes that I’ve seen get incredibly complex. I remember a customer who wanted to use Right Media’s serving system as the source of inventory but then inject behavioral information from his own cookie domain. The end result was that impressions came into the RM adserver, were redirected to his adserver and then were immediately redirected back to the RM serving system. That’s three ad-calls before an advertiser had even been selected!
That’s about it for now … Stay tuned for part III….
Redirects and Integration, Part I: Limitations
February 11th, 2008
Most integrations between ad-companies that want better collaboration between their platforms/technologies/serving-systems involve inserting one parties ad/pixel/click call into the redirect stream. For example, if a Contextual engine wants to pass information about a page to an ad-network, the only real way to do that today is as follows:
- Publisher replaces ad-call with a call to contextual provider
- Users are now redirected to contextual provider first
- Contextual provider checks the page, finds relevant keywords
- Contextual provider redirects user to the ad-network with the relevant keywords inserted into the ad-call.
In reality most ad-calls involve multiple networks, each of which of course wants to integrate with various third-party technologies. The end result is an ad-call stream that can have four or five redirects before finally reaching the actual advertiser.
So what’s wrong with this you may ask? Well, there are a couple major issues with this redirect method of “integration”:
Redirects are inherently insecure. Redirects make the client’s browser responsible for “integration”. This means that any “integration” is entirely public, both to the end-user, any party that might be sniffing traffic in-between and perhaps most importantly — the party you are integrating with. When you insert a partner into the ad-call redirect stream they have full control over both the user’s cookie and the ad-request. Taking the contextual provider example above, the contextual engine that’s adding it’s data to the ad-request has the ability to start building a behavioral profile of the user, without you ever being the wiser.
Redirects slow down ad-requests. This results in a bad user-experience and dropped impressions. Each additional redirect results in about 3-5% of impressions lost. Of course this number varies on the speed of your serving systems and the end-users internet connection.
Redirects force linear one-way integration. Each party can only “pass off” the impression to the next — it is nearly impossible to reliably “pass back” information to the publisher who passed you the impression. This means that all impression level communication is ‘one-way’ — severely limiting the level of integration between companies. Why might you want ‘two-way’ communication? What if you could just ask a Network how much an individual user is worth to it? What if instead of having to insert a Contextual provider into the redirect stream you could just do a live ping? How about passing the user’s browsing history as you know it to an analytics company to build an “on-the-fly” profile? None of the above is easily done today.
This concept seems to be confusing to a lot of people, so in this post I thought I’d compare more traditional Web 2.0 “integration” without todays’ online advertising “integration.
The Traditional Web 2.0 Way
Let’s imagine that I decide that I want to display the 4 latest images from my Flickr account on the homepage of my website. To accomplish this I put some code into my web-server that pings the Flickr API on every page load and downloads the latest four photos that I’ve taken. The following diagram illustrates this:
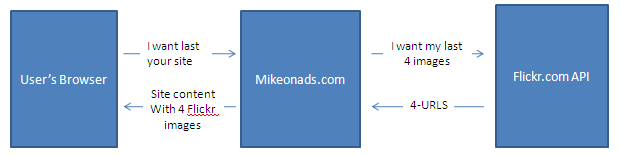
Notice something very important — Flickr is never in direct communication with the user on my site. The only information they see is what my webserver sends them in the API request.
Of course this extra API call will slow down my site a little bit. The total time this takes to serve my homepage is limited by the speed of the user’s internet connection to my webserver plus the however long it takes for my webserver to query the Flickr API. If we assume the average cable modem can get to my site and back in about 500ms, and it takes my webserver about 100ms to query content from the Flickr API then the total time to serve my page will be a little over 600ms. If the Flickr API stops responding or slows down drastically I can simply time out the request after 200ms and serve my homepage without my favorite images. So the MAX response time is simply:
Now I decide that in addition to four Flickr photos I want to display four of my favorite Delicious bookmarks. So on each web-page request:
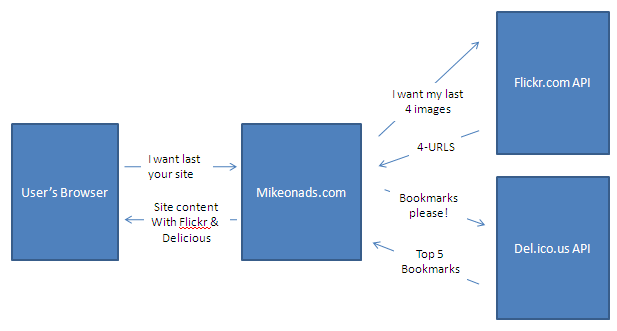
Notice that now my webserver goes off and sends off two concurrent parallel requests, one to Flickr and another to Delicious. Neither Flickr nor Delicious has direct access to my users as all communication must pass through my webserver first. Just as in the first example, I set a timeout of 200ms on both of my external API requests. So my response time:
Notice this is exactly the same max response time as with only a Flickr integration.
The Online Advertising Way
Now lets compare the “Web 2.0″ way with the online advertising way. Lets imagine that Mikeonads.com is working with “Network A”. Network A has contracted with a Contextual engine to scrape page content and extract relevant keywords for better targeted advertising. To do this the Network provided the publishers with an ad tag that points directly to the contextual provide. This means that every time a user visits Mikeonads.com he first requests the ad from the Contextual provider, who then redirects the user over to Network A inserting some relevant keywords into the ad-request. The following diagram illustrates this:
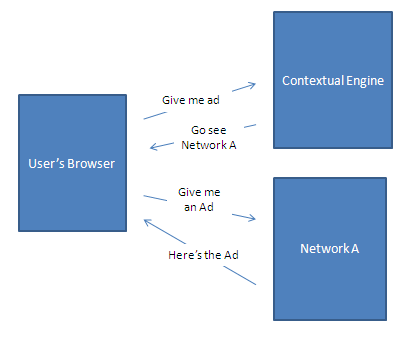
The first thing to notice here is that the user’s browser is actually making two completely separate sequential requests. This means that the contextual provider gets full access to his cookies on the user’s browser, and whatever information he can pull from server-headers & javascript: IP address, geo-location, page URL, etc. etc. Now some people might not care, but depending on the publisher this might be valuable data and fully exposing this is something that you really just want to avoid. This is the security risk I mentioned above.
Let’s analyze the response times. In this case, we have two separate requests to two separate serving systems. This means that the response time will be will be two round trips from the user’s browser to a serving system plus whatever processing time is required for each server. The reason we have to double up the user connection speed is because the browser cannot download the second request is until it has fully completed the first one. Taking the same 500ms round-trip number from above, and 10ms processing time we get:
Notice that this is already significantly slower than the Mikeonads<->Flickr integration. Now lets imagine that Network A decides that Mikeonads.com users aren’t very valuable and sells them off to Network B. In this case:
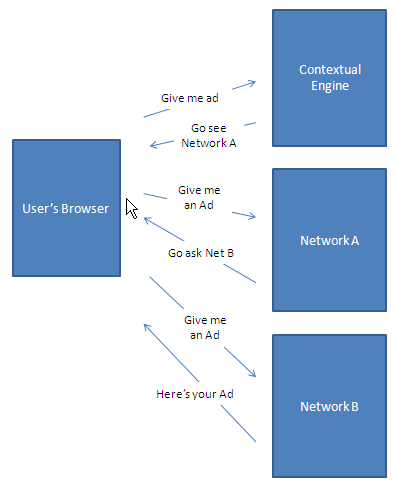
Now notice there are three different parties that each have full access to both the cookie and the javascript DOM tree. This means that each of these has an opportunity to install tracking cookies, install malicious software, etc. Maximum response time also increases drastically. We now have 3 full round-trips that happen sequentially, and hence our response time is:
Yikes! Total time has grown to 1.5s already! As you’ve probably deduced, if we throw in another serving system the time jumps to 2 seconds, add another we get to 2.5s. No wonder we lose 3-5% for every redirect! The problem simply gets worse and worse as the user’s internet connection gets slower.
The One-Way Limitation
I think the two examples above clearly show both the security & latency restrictions that arise from redirect based integration. The limitation of the “one way” are a little more subtle.
Control: Notice that in the ‘two-way’ Web 2.0 integration the Mikeonads webserver has an opportunity to make a decision based on the responses it receives from either Flickr or Delcious. For example, I could choose to exclude bookmarks tagged as “Suggestive in Nature”. In the online-ad example, Network A has no control over what content Network B returns to the user. There is nothing stopping Network B from showing an adult ad, or attempting to install some Malware on the user’s machine.
Accountability: Network A has no way of knowing whether Network B actually receives the impression. In fact, as mentioned earlier in many cases the user may simply browse to a new page before Network B has a chance to serve an ad. This leads to discrepancies in counting. In the two-way communication, not that Flickr cares, but if they were counting they would know exactly how many times Mikeonads served a web page with Flickr images.
Blindness: Before Network A redirects to Network B he has no clue what is going to happen financially. If he has a revenue-share agreement he doesn’t know how much money he will make until after the fact. Not only that, but there is no way for Network A to ever put an exact value on an individual impression as the data he receives back from Network B will be aggregated up.
There are many more subtle limitations as well. But rather than focus on listing them here, in the next post I will dig into the “one-wayness” of redirects, potential work-arounds and the gains to be had by fixing this problem.
Malicious Ads getting More Attention — People Still Clueless
November 22nd, 2007
So while reading my blog reader this morning I realized there were quite a large # of posts about malicious ads (aka Errorsafe) coming through. All this new media attention to the problem is good, but saddening that people still see so clueless. Perhaps even worse is the fact that industry folks don’t have a good grasp on the problem yet.
Take this eweek article on malicious ads. Lets look at some of their findings:
There is, in fact, a scourge of so-called “badvertising” infiltrating legitimate sites. Since Sept. 22, the ads have been finding their way into the servers of the advertising industry’s biggest players, such as DoubleClick.
Wow… these guys are really up to date. I created my “Errorsafe” page on March 22nd of 2007, and that’s after many months of frustration with malicious flash banner ads. The first “major” infiltration I know of dates to the summer of 2006 when Myspace served a malicious ad to its users. The tools & technology haven’t changed — the code might be more obfuscated, but it’s still the same type of flash ad executing similar javascript. Oh, and Myspace used DoubleClick for hosting back then.
If only it were so simple. In fact, there is no such anti-spyware that could be built into an ad-serving platform such as DoubleClick. The buyers who are purchasing advertising space on sites and then swapping in malicious ads are far too sophisticated to code their malicious code with something so crude as to be picked up by anti-spyware software.
Of course it’s possible to detect these ads, it just takes a little bit of work. Right Media has such a system. I’m also aware of at least two different companies that are looking to develop similar automated testing tools.
“The big issues that security researchers who deal with Web exploits and downloaders on Web pages struggle with every day are the different ways you can make JavaScript do different things. As long as you accept Flash and it has ActionScript, there’s no way to rule out a repeat of this fiasco.”
Not true. I proposed a fix in this post that should be fairly trivial to implement. Instead of assuming that actionscript is safe, everyone should assume that it’s unsafe. Then, the few ads that require special permissions (such as complex rich media ads) can go through a manual review and receive explicit permission to execute script.
So here’s my proposal — What if the industry giants got together and created one central repository of “safe ads”. This non-profit central body would do a manual audit of all the action-script within all ads and certify them as safe to run. Then, instead of emailing creatives around buyers would send an ID or link to the ad in the central repository. It’s a lot of work, but considering how much money is on the line, I’m sure it’d be fairly easy to get some funding together to do this.
Yahoo, Google, Microsoft — somebody up for setting this up? I’ll help =).
My absence
October 29th, 2007
Just wanted to write a quick note — I haven’t written a post in ages because I’m in the process of starting a new venture. New venture -> lots and lots of work -> very little time to blog. I promise I’ll write some more things soon, and also that I’ll post a link to the new venture. For now, if anybody knows any really solid systems administrators or senior web-guys, please send them my way!
Exchange v. Network Part II: Adoption
September 2nd, 2007
Exchange v. Network, Part II: Which platform to adopt
So in part I of this series I talked about the differences between Exchanges and Ad-Networks. Now that we understand the differences — lets talk about exchange adoption.
Blue-Ray v. HD-DVD
An interesting analgoy can be drawn between the upcoming exchange battle and the fight between Blue-Ray and HD-DVD over the next DVD format. There are pros and cons between Blue-Ray and HD-DVD, one is more expensive to build hardware for but has more storage space on the actual disks. Similarly there are differences between the various exchanges. Right Media has better optimization and remnant inventory management tools whereas DoubleClick dominates the premium/guaranteed market.
The thing is, when it comes to platforms the true value is the level adoption. Blue-Ray could be a far superior standard to HD-DVD, but if every movie studio only publishes the latter, what type of player would you buy for your home entertainment center? Similarly, an ad platform with terrific technology is useless if there aren’t buyers and sellers there to support it.
The most frustrating outcome of this HD battle would be if neither party wins. Just like the good old “-R” vs “+R” days with burnable CDs, everyone will have to spend more to support both. Instead of making a million CD-R discs, manufacturers had to split their output between “-R” and “+R”, decreasing the economies of scale and again driving up costs. DVD player manufacturers will have to build extra-powerful players than can support both disc types. If only everyone could agree today to back one standard then everyone would be better off.
Back to online advertising — the chances that any of the coming platforms will “win” are pretty slim. Imagine for a second that it was just Yahoo & Google who had ad platforms. Both companies could dump 100% of their search inventory into their respective marketplaces and instantly have enough inventory there to attract a large number of advertisers. In other words, Google can launch an “ad-exchange” that only consists of Adsense and Adwords and it would be a perfectly viable and liquid platform.
Now What
Assuming that that’s not going to happen and we will have multiple ‘standards’ out there, which one if any does a publisher or advertiser choose? What about a network? Although everyone can work with multiple exchanges, you can only adopt one. The problem is, most of the benefits come from true adoption.
First off there’s the basic reinforcement effect that advertisers go where the inventory is, and publishers go where the dollars are. The more members of an exchange, the more likely it’s to grow. Second there are the technical benefits that come with a single platform. For all those benefits — check out this older post on exchanges.
Whether or not you should adopt one of the platforms depends greatly on your business. For some, the free adserving provided by direct media exchange might be enough and the addition of integrated exchange partners is a nice bonus. On the other hand if you’re selling 95% guaranteed and happy with DFP then you’re probably better off waiting until the different players truly start to differentiate themselves.
Next up: How publishers can prioritize groups of buyers (e.g. networks or exchanges).
I am no longer with Right Media/Yahoo
August 31st, 2007
I apologize for the lack of posts the past two weeks but I’ve been busy wrapping some things up at work. Today was my last day at Right Media. It’s been an absolutely terrific ride watching the company grow from 40 to 200+ to an acquisition by Yahoo. I wish everyone at Right Media and Yahoo the best of luck. I haven’t solidified my plans for what’s next yet but I’ll be sure to update everyone once I have!
And one more errorsafe…
August 3rd, 2007
Sorry missed one more –this one from mobi.dada.net

It’s time to drive for simpler integration
August 2nd, 2007
So take this scenario. Your company just signed a huge deal with Avenue-A. You’ve just gotten a million dollars to spend for the quarter, it’s the big break you’ve been waiting for! You send your ops guy Marvin to coordinate the details with Avenue-A’s people and open a bottle of bubbly to celebrate. A week later you pull some reports and realize that you haven’t run a single impression yet. You yell out —
”MAARVVIIIIIIIIIIIIN!!!!!”.
”Yes sir?”
”Why the hell isn’t the Avenue-A deal running?”
”Oh, we couldn’t get click-tracking to work yet. I’ve got a ticket into support.”
Sound familiar? How about trying to get behavioral pixels live on a publisher’s page? Enabling age & gender passing on ad-calls for custom optimization? These mundane seemingly simple tasks can take weeks. Why? normal people using complex technical products.
Read this quote from the MSN Games 300×250 ad standards:
(A) Click-through tracking is not available on the following advertising elements:
• HTML advertising elements that use method=”POST” for form submittal.
• Rich media elements that use embedded or compiled URL information (Macromedia Flash creatives that do not use the FS command, for example).
• Third party served HTML (IFrame) campaigns.
(B) Cache-busting is available automatically for pre-approved third party served agencies, others by request only. Exception: Third party served click URLs for hard-coded placements (text links, etc.) are not cache busted. Therefore, MSN click data for hard-coded placements using third party served click URLs may not match click data from the third party agency. Please enter the Cache busting tags; MSN is not responsible for entering these tags.
I can’t be the only one that thinks that this is absolutely ridiculous. How can it possibly take five days to get an ad live? This is a process that should take mere hours! Why should people know the difference between method=”GET” and “POST”? Your average media-buyer probably has a degree in English, your ad-ops guy? History? Philosophy? It shouldn’t be the least bit surprising that these people have so much trouble doing what those of us with technical knowledge may find simple.
By nature what we do is technical, it is called online advertising! Purely from a technical perspective we cant buy or sell inventory without snippets of HTML that enable communication and highly complex adservers to do decisioning and optimization. What makes matters worse is that most ad-impressions involve two adservers, if not many more. The way things work today, these systems can’t talk to each-other directly and all communication must pass through the browser, which only reads HTML, XML, Javascript, Java, etc… more technical things!
Yet, just because adservers can’t communicate without HTML, Javascript and redirects doesn’t mean that users should have to worry about these details. Come on! Think of WordPress or Blogger, both services that have brought web-publishing to the masses. They have abstracted almost all technical aspects of blogging allowing anybody to post their thoughts online — why can’t we do the same in our products? I’m not sure I have a solution right this second, but perhaps we should begin by re-examining what is considered “normal” today. Here’s my list:
- Knowledge of HTML is needed to enable clicktracking/li>
- 5 days is considered normal and acceptable turnaround time for trafficking third party ads
- Passing user data between systems involves knowledge of querystrings
- Adservers have vastly different standards, heck, users need to know whether to encode or not
- None of the above can be implemented without a “test” to confirm it really works
Most of the above stem from the fact that we have many different platforms, a situation that is unlikely to change in the foreseeable future. Sure, if both the advertiser and the publisher are using one system things are easy — DART has internal redirects, Right Media has linking and I’m sure others have or will invent similar concepts. The problem is, there will always be advertisers and publishers that will work with all three systems — which the way things look today means more redirects, click-tracking and long delays to activate campaigns or setup tags.
So product managers, architects and engineers, I think it’s time to put on your thinking caps to figure out how systems can better work together to make the day to day lives of the people who actually use said systems much easier. A million dollar Avenue-A deal should never hinge on a trafficker editing the HTML of the ad-tags to enable click-tracking.