






Redirects and Integration, Part I: Limitations
February 11th, 2008
Most integrations between ad-companies that want better collaboration between their platforms/technologies/serving-systems involve inserting one parties ad/pixel/click call into the redirect stream. For example, if a Contextual engine wants to pass information about a page to an ad-network, the only real way to do that today is as follows:
- Publisher replaces ad-call with a call to contextual provider
- Users are now redirected to contextual provider first
- Contextual provider checks the page, finds relevant keywords
- Contextual provider redirects user to the ad-network with the relevant keywords inserted into the ad-call.
In reality most ad-calls involve multiple networks, each of which of course wants to integrate with various third-party technologies. The end result is an ad-call stream that can have four or five redirects before finally reaching the actual advertiser.
So what’s wrong with this you may ask? Well, there are a couple major issues with this redirect method of “integration”:
Redirects are inherently insecure. Redirects make the client’s browser responsible for “integration”. This means that any “integration” is entirely public, both to the end-user, any party that might be sniffing traffic in-between and perhaps most importantly — the party you are integrating with. When you insert a partner into the ad-call redirect stream they have full control over both the user’s cookie and the ad-request. Taking the contextual provider example above, the contextual engine that’s adding it’s data to the ad-request has the ability to start building a behavioral profile of the user, without you ever being the wiser.
Redirects slow down ad-requests. This results in a bad user-experience and dropped impressions. Each additional redirect results in about 3-5% of impressions lost. Of course this number varies on the speed of your serving systems and the end-users internet connection.
Redirects force linear one-way integration. Each party can only “pass off” the impression to the next — it is nearly impossible to reliably “pass back” information to the publisher who passed you the impression. This means that all impression level communication is ‘one-way’ — severely limiting the level of integration between companies. Why might you want ‘two-way’ communication? What if you could just ask a Network how much an individual user is worth to it? What if instead of having to insert a Contextual provider into the redirect stream you could just do a live ping? How about passing the user’s browsing history as you know it to an analytics company to build an “on-the-fly” profile? None of the above is easily done today.
This concept seems to be confusing to a lot of people, so in this post I thought I’d compare more traditional Web 2.0 “integration” without todays’ online advertising “integration.
The Traditional Web 2.0 Way
Let’s imagine that I decide that I want to display the 4 latest images from my Flickr account on the homepage of my website. To accomplish this I put some code into my web-server that pings the Flickr API on every page load and downloads the latest four photos that I’ve taken. The following diagram illustrates this:
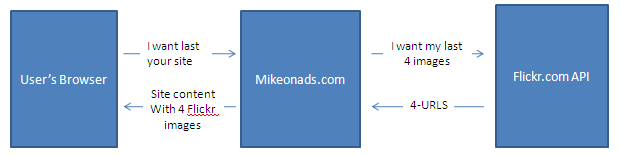
Notice something very important — Flickr is never in direct communication with the user on my site. The only information they see is what my webserver sends them in the API request.
Of course this extra API call will slow down my site a little bit. The total time this takes to serve my homepage is limited by the speed of the user’s internet connection to my webserver plus the however long it takes for my webserver to query the Flickr API. If we assume the average cable modem can get to my site and back in about 500ms, and it takes my webserver about 100ms to query content from the Flickr API then the total time to serve my page will be a little over 600ms. If the Flickr API stops responding or slows down drastically I can simply time out the request after 200ms and serve my homepage without my favorite images. So the MAX response time is simply:
Now I decide that in addition to four Flickr photos I want to display four of my favorite Delicious bookmarks. So on each web-page request:
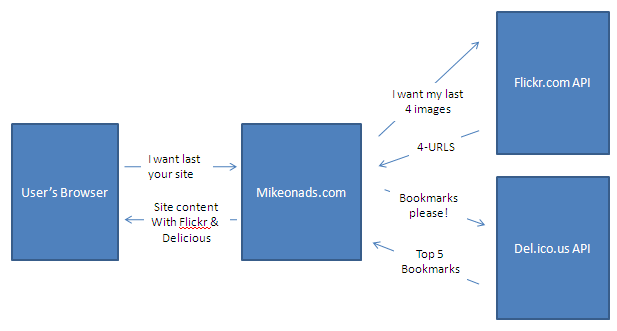
Notice that now my webserver goes off and sends off two concurrent parallel requests, one to Flickr and another to Delicious. Neither Flickr nor Delicious has direct access to my users as all communication must pass through my webserver first. Just as in the first example, I set a timeout of 200ms on both of my external API requests. So my response time:
Notice this is exactly the same max response time as with only a Flickr integration.
The Online Advertising Way
Now lets compare the “Web 2.0″ way with the online advertising way. Lets imagine that Mikeonads.com is working with “Network A”. Network A has contracted with a Contextual engine to scrape page content and extract relevant keywords for better targeted advertising. To do this the Network provided the publishers with an ad tag that points directly to the contextual provide. This means that every time a user visits Mikeonads.com he first requests the ad from the Contextual provider, who then redirects the user over to Network A inserting some relevant keywords into the ad-request. The following diagram illustrates this:
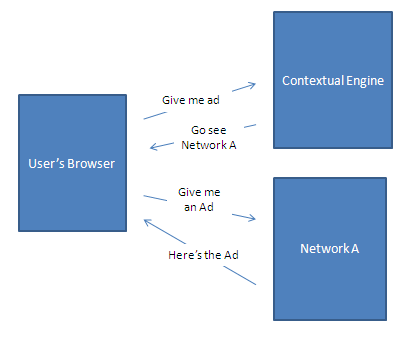
The first thing to notice here is that the user’s browser is actually making two completely separate sequential requests. This means that the contextual provider gets full access to his cookies on the user’s browser, and whatever information he can pull from server-headers & javascript: IP address, geo-location, page URL, etc. etc. Now some people might not care, but depending on the publisher this might be valuable data and fully exposing this is something that you really just want to avoid. This is the security risk I mentioned above.
Let’s analyze the response times. In this case, we have two separate requests to two separate serving systems. This means that the response time will be will be two round trips from the user’s browser to a serving system plus whatever processing time is required for each server. The reason we have to double up the user connection speed is because the browser cannot download the second request is until it has fully completed the first one. Taking the same 500ms round-trip number from above, and 10ms processing time we get:
Notice that this is already significantly slower than the Mikeonads<->Flickr integration. Now lets imagine that Network A decides that Mikeonads.com users aren’t very valuable and sells them off to Network B. In this case:
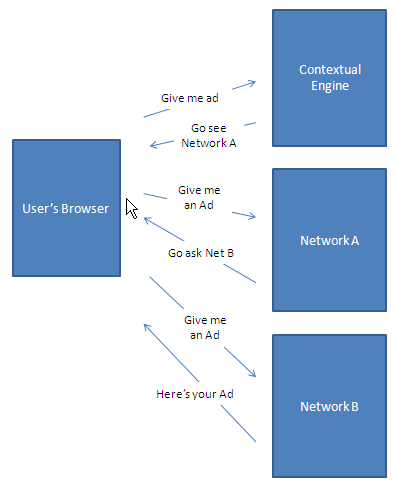
Now notice there are three different parties that each have full access to both the cookie and the javascript DOM tree. This means that each of these has an opportunity to install tracking cookies, install malicious software, etc. Maximum response time also increases drastically. We now have 3 full round-trips that happen sequentially, and hence our response time is:
Yikes! Total time has grown to 1.5s already! As you’ve probably deduced, if we throw in another serving system the time jumps to 2 seconds, add another we get to 2.5s. No wonder we lose 3-5% for every redirect! The problem simply gets worse and worse as the user’s internet connection gets slower.
The One-Way Limitation
I think the two examples above clearly show both the security & latency restrictions that arise from redirect based integration. The limitation of the “one way” are a little more subtle.
Control: Notice that in the ‘two-way’ Web 2.0 integration the Mikeonads webserver has an opportunity to make a decision based on the responses it receives from either Flickr or Delcious. For example, I could choose to exclude bookmarks tagged as “Suggestive in Nature”. In the online-ad example, Network A has no control over what content Network B returns to the user. There is nothing stopping Network B from showing an adult ad, or attempting to install some Malware on the user’s machine.
Accountability: Network A has no way of knowing whether Network B actually receives the impression. In fact, as mentioned earlier in many cases the user may simply browse to a new page before Network B has a chance to serve an ad. This leads to discrepancies in counting. In the two-way communication, not that Flickr cares, but if they were counting they would know exactly how many times Mikeonads served a web page with Flickr images.
Blindness: Before Network A redirects to Network B he has no clue what is going to happen financially. If he has a revenue-share agreement he doesn’t know how much money he will make until after the fact. Not only that, but there is no way for Network A to ever put an exact value on an individual impression as the data he receives back from Network B will be aggregated up.
There are many more subtle limitations as well. But rather than focus on listing them here, in the next post I will dig into the “one-wayness” of redirects, potential work-arounds and the gains to be had by fixing this problem.
Related Posts:
- Redirects and Integration, Part II: Hacking Around the Browser
- RTB Part I: What is it?
- Can’t we all just 302? Report on redirect timings
- RTB Serving Speed
- Adotas Premium v. Remnant Series
-
http://yardley.ca/2008/02/11/on-redirects-avoiding-them/ yardley.ca » On redirects & avoiding them
-
Mike
-
http://hypergeometric.com gpapilion
-
http://mukulblog.blogspot.com Mukul Kumar
-
http://www.mikeonads.com/2008/04/17/redirects-and-integration-part-ii-hacking-around-the-browser/ Mike On Ads » Blog Archive » Redirects and Integration, Part II: Hacking Around the Browser
-
http://www.zip-repair.org/ zip file repair download